Deploying BibXML Service in AWS EKS Fargate
 on
07 Jan 2021
on
07 Jan 2021
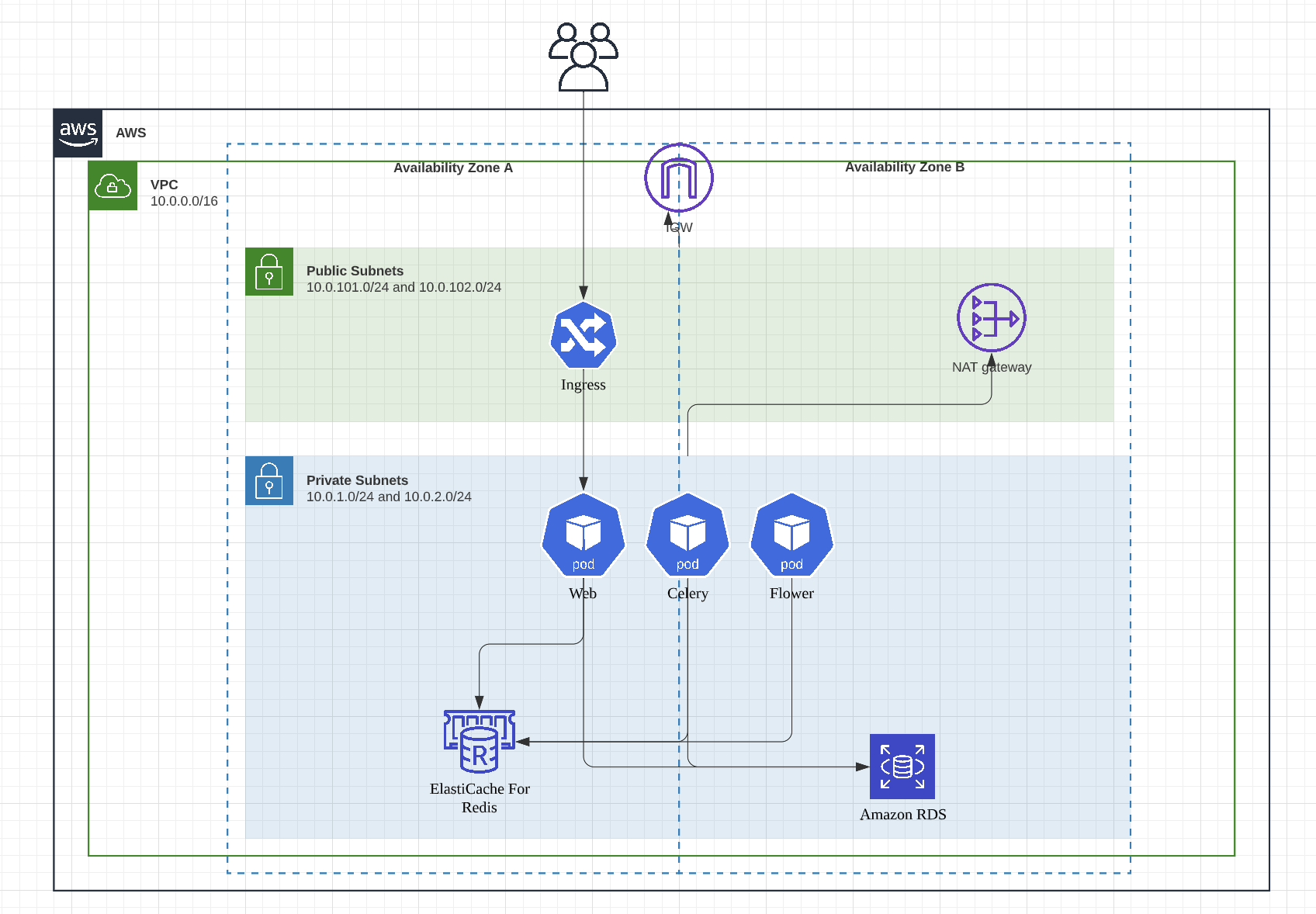
In this article, we will use BibXML Service (Django-based Web service implementing IETF BibXML APIs) as a showcase to show you how to deploy containerized Python and Django applications in AWS EKS Fargate.
Prerequisites
You may need to learn the technologies listed below to understand the steps listed in this article.
Introduction
BibXML Service is Django-based Web service implementing IETF BibXML APIs.
It consists of:
-
BibXML Service web application
-
BibXML Service web application is the frontend application. It will be built as a docker image.
-
-
Celery
-
Celery is used to run background jobs. The docker image of it is the same as BibXML Service with different entrypoint.
-
-
Flower
-
Flower is a tool to monitor Celery. It will be launched by using the official docker image.
-
-
PostgreSQL
-
PostgreSQL will be deployed by using AWS RDS.
-
-
Redis
-
Redis will be deployed by using AWS ElastiCache.
-
-
Database migration
-
A Kubernetes Job is used to run database migration.
-
Create VPC
First of all, we will create a VPC with 2 public subnets and 2 private subnets.
To create AWS VPC, define provider in provider.tf.
provider "aws" {
region = var.aws-region
allowed_account_ids = [var.aws-account-ids]
}Define variables in variables.tf.
variable "aws-account-ids" {
default = "12345678"
}
variable "aws-region" {
default = "us-east-1"
}
variable "name" {
default = "my-app"
}
variable "eks_cluster_name" {
default = "my-eks-cluster"
}
variable "vpc-cidr" {
description = "CIDR for the vpc"
default = "10.0.0.0/16"
}
variable "azs" {
description = "A list of availability zones for the vpc"
type = list(string)
default = ["us-east-1a", "us-east-1b"]
}
variable "private_subnets" {
description = "A list of public subnets for the vpc"
type = list(string)
default = ["10.0.1.0/24", "10.0.2.0/24"]
}
variable "public_subnets" {
description = "A list of private subnets for the vpc"
type = list(string)
default = ["10.0.101.0/24", "10.0.102.0/24"]
}
variable "zone_count" {
type = number
default = 2
}Define VPC in vpc.tf.
resource "aws_vpc" "main" {
cidr_block = "${var.vpc-cidr}"
instance_tenancy = "default"
enable_dns_hostnames = true
enable_dns_support = true
tags = {
"Name" = "${var.name}-vpc"
}
}Define resources in public subnets in public.tf. By using count,
2 subnets will be created accordingly.
|
Note
|
Public subnets are used for internet-facing load balancers.
For the use of Kubernetes Subnet Auto Discovery, these subnets should be
tagged with:
kubernetes.io/role/elb: 1
Both private and public subnets should be tagged with:
kubernetes.io/cluster/${var.eks_cluster_name}: owned
|
resource "aws_subnet" "public" {
vpc_id = "${aws_vpc.main.id}"
cidr_block = element(var.public_subnets, count.index)
availability_zone = element(var.azs, count.index)
map_public_ip_on_launch = true
count = var.zone_count
tags = {
"Name" = "${var.name}-public-subnet-${count.index}"
"kubernetes.io/role/elb" = "1"
"kubernetes.io/cluster/${var.eks_cluster_name}" = "owned"
}
}Define Internet Gateway and routes in public.tf to allow resources
with public subnet to access the internet.
resource "aws_internet_gateway" "main" {
vpc_id = aws_vpc.main.id
tags = {
"Name" = "${var.name}-internet-gateway"
}
}
resource "aws_route_table" "public" {
vpc_id = aws_vpc.main.id
tags = {
"Name" = "${var.name}-public-route-table"
}
}
resource "aws_route" "public" {
destination_cidr_block = "0.0.0.0/0"
route_table_id = aws_route_table.public.id
gateway_id = aws_internet_gateway.main.id
}
locals {
public_subnet_ids = concat(aws_subnet.public.*.id)
}
resource "aws_route_table_association" "public" {
count = var.zone_count
route_table_id = aws_route_table.public.id
subnet_id = local.public_subnet_ids[count.index]
}Define private subnets in private.tf.
|
Note
|
Private Subnets should be tagged with:
kubernetes.io/role/internal-elb: 1
Both private and public subnets should be tagged with:
kubernetes.io/cluster/${var.eks_cluster_name}: owned
|
resource "aws_subnet" "private" {
vpc_id = "${aws_vpc.main.id}"
cidr_block = element(var.private_subnets, count.index)
availability_zone = element(var.azs, count.index)
map_public_ip_on_launch = false
count = var.zone_count
tags = {
"Name" = "${var.name}-private-subnet-${count.index}"
"kubernetes.io/role/internal-elb" = "1"
"kubernetes.io/cluster/${var.eks_cluster_name}" = "owned"
}
}Create a NAT Gateway and routes in private.tf to allow resources in
private subnets to connect to services outside your VPC but external services
cannot initiate a connection with those resources. An Elastic IP (EIP) is
required for NAT Gateway.
|
Note
|
NAT Gateway should be created in public subnet to route traffics from private subnets to outside. |
resource "aws_eip" "nat" {
vpc = true
public_ipv4_pool = "amazon"
}
locals {
private_subnet_ids = concat(aws_subnet.private.*.id)
}
resource "aws_nat_gateway" "main" {
allocation_id = aws_eip.nat.id
subnet_id = local.public_subnet_ids[0]
connectivity_type = "public"
tags = {
"Name" = "${var.name}-nat-gateway"
}
depends_on = [
aws_eip.nat,
aws_subnet.private,
]
}
resource "aws_route_table" "private" {
count = var.zone_count
vpc_id = aws_vpc.main.id
tags = {
"Name" = "${var.name}-private-route-table-${count.index}"
}
}
locals {
route_table_ids = concat(aws_route_table.private.*.id)
}
resource "aws_route" "private" {
count = var.zone_count
destination_cidr_block = "0.0.0.0/0"
route_table_id = local.route_table_ids[count.index]
nat_gateway_id = aws_nat_gateway.main.id
}
resource "aws_route_table_association" "private" {
count = var.zone_count
route_table_id = local.route_table_ids[count.index]
subnet_id = local.private_subnet_ids[count.index]
}By running terraform apply, a VPC with public and private subnets will be
created.
Create EKS cluster
To use AWS EKS, define EKS cluster and EKS Cluster Role and in eks.tf.
As we are going to deploy pods in Fargate, we need to set the subnets to
private subnets.
Kubernetes clusters managed by Amazon EKS make calls to other AWS services on your behalf to manage the resources that you use with the service. EKS Cluster Role should be defined to achieve this purpose.
resource "aws_eks_cluster" "main" {
name = "${var.eks_cluster_name}"
role_arn = aws_iam_role.eks_cluster_role.arn
vpc_config {
subnet_ids = concat(aws_subnet.private.*.id)
}
tags = {
"kubernetes.io/cluster/${var.eks_cluster_name}" = "owned"
}
timeouts {
delete = "30m"
}
depends_on = [
aws_iam_role.eks_cluster_role,
aws_iam_role_policy_attachment.eks-AmazonEKSClusterPolicy,
aws_iam_role_policy_attachment.eks-AmazonEKSVPCResourceController,
]
}
resource "aws_iam_role" "eks_cluster_role" {
name = "${var.eks_cluster_name}-role"
force_detach_policies = true
assume_role_policy = <<POLICY
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"eks.amazonaws.com",
"eks-fargate-pods.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
POLICY
}
resource "aws_iam_role_policy_attachment" "eks-AmazonEKSClusterPolicy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy"
role = aws_iam_role.eks_cluster_role.name
}
resource "aws_iam_role_policy_attachment" "eks-AmazonEKSVPCResourceController" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSVPCResourceController"
role = aws_iam_role.eks_cluster_role.name
}Fargate Profiles
In order to run pods in Fargate (Serverless mode), you need to create Fargate
Profile with related role in fargate.tf.
If the namespace or other selectors such as labels of a pod matches the selector of a Fargate profile, the pod will use that profile and run in Fargate.
CoreDNS is the DNS server for Kubernetes. By default, it will be
run in node (EC2 instance). You need to instruct it to run in Fargate.
The namespace of CoreDNS is kube-system. Therefore you need to create a
Fargate Profile with namespace: kube-system and patch the deployment of
CoreDNS to run in Fargate.
Replace ${fargate_profile_name} with kube-system-fp and ${namespace} with
kube-system. Apply Changes by Terraform.
resource "aws_eks_fargate_profile" "main" {
fargate_profile_name = ${fargate_profile_name}
cluster_name = var.eks_cluster_name
subnet_ids = concat(aws_route_table.private.*.id)
pod_execution_role_arn = aws_iam_role.fp-role.arn
selector {
namespace = ${namespace}
}
timeouts {
create = "30m"
delete = "30m"
}
}
data "aws_iam_policy_document" "fp-assume_role" {
statement {
effect = "Allow"
actions = ["sts:AssumeRole"]
principals {
type = "Service"
identifiers = [
"eks.amazonaws.com",
"eks-fargate-pods.amazonaws.com",
]
}
}
}
resource "aws_iam_role" "fp-role" {
name = "${fargate_profile_name}-role"
assume_role_policy = data.aws_iam_policy_document.fp-assume_role.json
}
resource "aws_iam_role_policy_attachment" "fp-AmazonEKSFargatePodExecutionRolePolicy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSFargatePodExecutionRolePolicy"
role = aws_iam_role.fp-role.name
}
resource "aws_iam_role_policy_attachment" "fp-AmazonEKSClusterPolicy" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSClusterPolicy"
role = aws_iam_role.fp-role.name
}
resource "aws_iam_role_policy_attachment" "fp-AmazonEKSVPCResourceController" {
policy_arn = "arn:aws:iam::aws:policy/AmazonEKSVPCResourceController"
role = aws_iam_role.fp-role.name
}Later you will run pods without specifying namespace. You need to create another Fargate Profile with namespace: default.
Replace ${fargate_profile_name} with default-fp and ${namespace} with
default with the code mentioned above.
Setup Kubeconfig
You can setup kubeconfig.
aws eks --region <aws-region> update-kubeconfig --name <my-eks-cluster-name>Now you can use kubectl to manage Kubernetes resources.
Patch CoreDNS
Use kubectl to patch the CoreDNS deployment to instruct the pods to run in
Fargate.
kubectl patch deployment coredns \
-n kube-system \
--type json \
-p='[{"op": "replace", "path": "/spec/template/metadata/annotations/eks.amazonaws.com~1compute-type", "value": "fargate"}]'
kubectl patch deployment coredns \
-n kube-system \
--type json \
-p='[{"op": "replace", "path": "/spec/template/metadata/labels/eks.amazonaws.com~1fargate-profile", "value": "kube-system-fp"}]'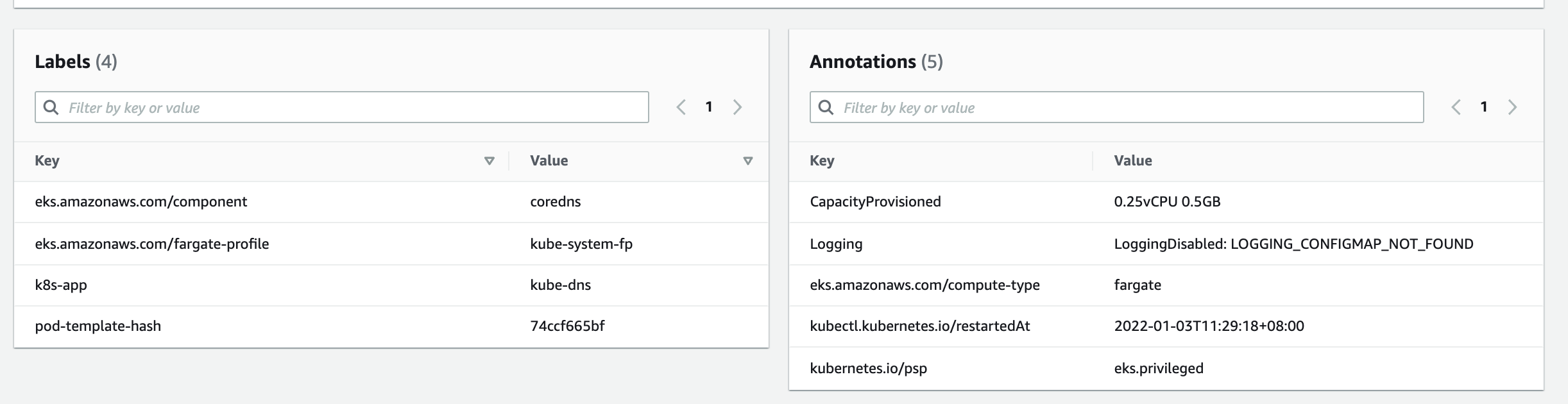
Restart CoreDNS
Restart CoreDNS by kubectl.
kubectl rollout restart -n kube-system deployment coredns
kubectl scale -n kube-system deployment/coredns --replicas=0
kubectl scale -n kube-system deployment/coredns --replicas=2Check CoreDNS Status
Now, you should check the status of CoreDNS.
kubectl get po -n kube-system -o wideYou should see CoreDNS pods are running in Fargate. The NODE output should look like:
NODE
fargate-ip-10-0-2-222.ec2.internalCreate PostgreSQL Database
Define PostgreSQL Database in db.tf.
resource "aws_db_instance" "main" {
identifier = var.name
instance_class = var.instance_class
allocated_storage = var.allocated_storage
engine = var.engine
engine_version = var.engine_version
username = var.db_username
password = var.db_password
db_subnet_group_name = aws_db_subnet_group.main.name
vpc_security_group_ids = [aws_security_group.rds.id]
parameter_group_name = aws_db_parameter_group.main.name
publicly_accessible = false
skip_final_snapshot = true
}
resource "aws_db_subnet_group" "main" {
name = "${var.name}-db-subnet-group"
subnet_ids = concat(aws_subnet.private.*.id)
tags = {
Name = "${var.name}-db-subnet-group"
}
}
resource "aws_db_parameter_group" "main" {
name = "${var.name}-db-parameter-group"
family = "postgres13"
parameter {
name = "log_connections"
value = "1"
}
}
### security groups
resource "aws_security_group" "rds" {
vpc_id = var.vpc_id
name_prefix = "${var.name}-rds-"
description = "${var.name}-rds-sg"
tags = {
Name = "${var.name}-rds-sg"
}
}
### ingress rules
resource "aws_security_group_rule" "rds_ingress_db" {
type = "ingress"
from_port = var.db_port
to_port = var.db_port
protocol = "tcp"
cidr_blocks = ["10.0.1.0/24", "10.0.2.0/24"]
security_group_id = aws_security_group.rds.id
}
### egress rules
resource "aws_security_group_rule" "rds_egress_db" {
type = "egress"
from_port = var.db_port
to_port = var.db_port
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
security_group_id = aws_security_group.rds.id
}Add variables in variables.tf for database.
variable "db_port" {
default = "<db-port>"
}
variable "db_username" {
description = "RDS root user username"
default = "<db-user>"
}
variable "db_password" {
description = "RDS root user password"
default = "<db-password>"
}
variable "instance_class" {
default = "db.t3.micro"
}
variable "allocated_storage" {
type = number
default = 10
}
variable "engine" {
default = "postgres"
}
variable "engine_version" {
default = "13.3"
}
variable "publicly_accessible" {
type = bool
default = false
}
variable "skip_final_snapshot" {
type = bool
default = true
}Create Redis
/*
* This module will create a redis server which is acessible from
* the private subnets of the VPC.
*/
resource "aws_elasticache_cluster" "redis" {
cluster_id = "${var.name}-redis-cluster"
engine = var.engine
engine_version = var.engine_version
node_type = var.node_type
num_cache_nodes = var.num_cache_nodes
parameter_group_name = var.parameter_group_name
port = var.redis_port
subnet_group_name = aws_elasticache_subnet_group.redis.name
security_group_ids = [aws_security_group.redis.id]
}
resource "aws_elasticache_subnet_group" "redis" {
name = "${var.name}-redis-subnet-group"
subnet_ids = concat(aws_subnet.private.*.id)
}
### security group
resource "aws_security_group" "redis" {
name_prefix = "${var.name}-redis-"
vpc_id = var.vpc_id
description = "${var.name}-redis-sg"
tags = {
Name = "${var.name}-redis-sg"
}
}
### ingress rules
resource "aws_security_group_rule" "redis_ingress" {
type = "ingress"
from_port = var.redis_port
to_port = var.redis_port
protocol = "tcp"
cidr_blocks = ["10.0.1.0/24", "10.0.2.0/24"]
security_group_id = aws_security_group.redis.id
}
### egress rules
resource "aws_security_group_rule" "redis_egress" {
type = "egress"
from_port = var.redis_port
to_port = var.redis_port
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
security_group_id = aws_security_group.redis.id
}Add variables in variables.tf for Redis.
variable "redis_port" {
default = "6379"
}
variable "engine" {
default = "redis"
}
variable "node_type" {
default = "cache.t3.micro"
}
variable "parameter_group_name" {
default = "default.redis6.x"
}
variable "engine_version" {
default = "6.x"
}
variable "num_cache_nodes" {
type = number
default = 1
}Database migration
Before the start the frondend web application, you may need to setup the schema
of the database. You can use Job to perform such one-off task.
You should define it in db-migrate.yaml.
apiVersion: batch/v1
kind: Job
metadata:
name: db-migration
spec:
template:
spec:
containers:
- name: db-migration
image: <aws-account-id>.dkr.ecr.<aws-region>.amazonaws.com/<ecr-image-name>:latest
args:
- /bin/sh
- -c
- python manage.py migrate && python manage.py check --deploy
env:
- name: DB_HOST
value: <db-hostname>
- name: DB_PORT
value: "<db-port>"
- name: DB_USER
value: <db-user>
- name: DB_NAME
value: postgres
- name: DB_SECRET
value: <db-password>
- name: CELERY_BROKER_URL
value: redis://<redis-host>:<redis-port>
- name: CELERY_RESULT_BACKEND
value: redis://<redis-host>:<redis-port>
- name: REDIS_HOST
value: <redis-host>
- name: REDIS_PORT
value: "<redis-port>"
restartPolicy: NeverRun Job
You can use kubectl to run the job.
kubectl apply -f db-migrate.yamlThe Job will pull the image from ECR and run the migration command defined in args.
Verify Job
You can verify the job by:
kubectl get po -o wideRun Web Application in Fargate Pod
Define the deployment of the web application and setup related environments in
web-deployment. Assume the pod will listen to port 8000.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
strategy:
type: Recreate
template:
metadata:
labels:
app: web
spec:
containers:
- name: web
image: <aws-account-id>.dkr.ecr.<aws-region>.amazonaws.com/<ecr-image-name>:latest
args:
- /bin/sh
- -c
- python manage.py collectstatic --noinput && daphne bibxml.asgi:application -p 8000 -b 0.0.0.0
ports:
- containerPort: 8000
env:
- name: DB_HOST
value: <db-hostname>
- name: DB_PORT
value: "<db-port>"
- name: DB_USER
value: <db-user>
- name: DB_NAME
value: postgres
- name: DB_SECRET
value: <db-password>
- name: API_SECRET
value: <api-secret>
- name: DATASET_TMP_ROOT
value: <tmp-folder>
- name: CELERY_BROKER_URL
value: redis://<redis-host>:<redis-port>
- name: CELERY_RESULT_BACKEND
value: redis://<redis-host>:<redis-port>
- name: REDIS_HOST
value: <redis-host>
- name: REDIS_PORT
value: "<redis-port>"To allow pod is accessible from outside, you need to define Service with type NodePort in web-service.yml.
apiVersion: v1
kind: Service
metadata:
name: web-service
spec:
type: NodePort
selector:
app: web
ports:
- port: 8000
targetPort: 8000
protocol: TCPRun pod and service for the web application.
kubectl apply -f web-deployment.yaml
kubectl apply -f web-service.yamlCheck pods and services are running.
kubectl get po,svc -o wideService Account for AWS Load Balancer Controller
In order to create AWS Ingress load balancer for the connecting internet and
Fargate pods. You need to setup a Service Account in service_account.tf.
### IAM policy for the controller
data "http" "iam_policy" {
url = "https://raw.githubusercontent.com/kubernetes-sigs/aws-load-balancer-controller/v2.3.1/docs/install/iam_policy.json"
request_headers = {
Accept = "application/json"
}
}
resource "aws_iam_policy" "sa-AWSLoadBalancerControllerIAMPolicy" {
name = "${var.name}-AWSLoadBalancerControllerIAMPolicy"
policy = data.http.iam_policy.body
}
data "aws_caller_identity" "current" {}
data "aws_iam_policy_document" "elb_assume_role_policy" {
statement {
actions = ["sts:AssumeRoleWithWebIdentity"]
effect = "Allow"
condition {
test = "StringEquals"
variable = "${replace(module.eks.eks_cluster.identity[0].oidc[0].issuer, "https://", "")}:sub"
values = ["system:serviceaccount:kube-system:aws-load-balancer-controller"]
}
principals {
identifiers = ["arn:aws:iam::${data.aws_caller_identity.current.account_id}:oidc-provider/${replace(module.eks.eks_cluster.identity[0].oidc[0].issuer, "https://", "")}"]
type = "Federated"
}
}
}
resource "aws_iam_role" "eks_lb_controller" {
assume_role_policy = data.aws_iam_policy_document.elb_assume_role_policy.json
name = "${var.name}-AmazonEKSLoadBalancerControllerRole"
}
resource "aws_iam_role_policy_attachment" "ALBIngressControllerIAMPolicy" {
policy_arn = aws_iam_policy.sa-AWSLoadBalancerControllerIAMPolicy.arn
role = aws_iam_role.eks_lb_controller.name
}
### service account
resource "kubernetes_service_account" "load_balancer_controller" {
automount_service_account_token = true
metadata {
name = "aws-load-balancer-controller"
namespace = "kube-system"
annotations = {
"eks.amazonaws.com/role-arn" = aws_iam_role.eks_lb_controller.arn
}
labels = {
"app.kubernetes.io/name" = "aws-load-balancer-controller"
"app.kubernetes.io/component" = "controller"
"app.kubernetes.io/managed-by" = "terraform"
}
}
}
resource "kubernetes_cluster_role" "load_balancer_controller" {
metadata {
name = "aws-load-balancer-controller"
labels = {
"app.kubernetes.io/name" = "aws-load-balancer-controller"
"app.kubernetes.io/managed-by" = "terraform"
}
}
rule {
api_groups = ["", "extensions"]
resources = ["configmaps", "endpoints", "events", "ingresses", "ingresses/status", "services"]
verbs = ["create", "get", "list", "update", "watch", "patch"]
}
rule {
api_groups = ["", "extensions"]
resources = ["nodes", "pods", "secrets", "services", "namespaces"]
verbs = ["get", "list", "watch"]
}
}
resource "kubernetes_cluster_role_binding" "load_balancer_controller" {
metadata {
name = "aws-load-balancer-controller"
labels = {
"app.kubernetes.io/name" = "aws-load-balancer-controller"
"app.kubernetes.io/managed-by" = "terraform"
}
}
role_ref {
api_group = "rbac.authorization.k8s.io"
kind = "ClusterRole"
name = kubernetes_cluster_role.load_balancer_controller.metadata[0].name
}
subject {
api_group = ""
kind = "ServiceAccount"
name = kubernetes_service_account.load_balancer_controller.metadata[0].name
namespace = kubernetes_service_account.load_balancer_controller.metadata[0].namespace
}
}Launch AWS Load Balancer Controller
kubectl apply -k "github.com/aws/eks-charts/stable/aws-load-balancer-controller//crds?ref=master"Patch and Restart AWS Load Balancer Controller
Patch AWS Load Balance Controller to make it run in Fargate.
kubectl patch deployment aws-load-balancer-controller \
-n kube-system \
--type json \
-p='[{"op": "replace", "path": "/spec/template/metadata/annotations/eks.amazonaws.com~1compute-type", "value": "fargate"}]'
kubectl patch deployment aws-load-balancer-controller \
-n kube-system \
--type json \
-p='[{"op": "replace", "path": "/spec/template/metadata/labels/eks.amazonaws.com~1fargate-profile", "value": "kube-system-fp"}]'
kubectl rollout restart -n kube-system deployment aws-load-balancer-controller
kubectl scale -n kube-system deployment/aws-load-balancer-controller --replicas=0
kubectl scale -n kube-system deployment/aws-load-balancer-controller --replicas=2Create Ingress Load Balancer
To allow Ingress Load Balancer to listen traffic from outside and forward the
traffic to the pod. You need to create an Ingress Load Balancer in public
subnets and forward the web-service defined above. In order to instruct
the Ingress Load Balancer to find the targets of Fargate pods, you must set
the annotations: alb.ingress.kubernetes.io/target-type: ip.
|
Note
|
The annotations of health check has been tuned for faster response. You may need to create a endpoint of health check in your code. |
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: web-ingress
labels:
app: web-ingress
annotations:
kubernetes.io/ingress.class: alb
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/inbound-cidrs: 0.0.0.0/0
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'
alb.ingress.kubernetes.io/subnets: <public-subnet1-id>, <public-subnet2-id>
alb.ingress.kubernetes.io/healthcheck-interval-seconds: '60'
alb.ingress.kubernetes.io/unhealthy-threshold-count: '5'
alb.ingress.kubernetes.io/healthcheck-timeout-seconds: '30'
alb.ingress.kubernetes.io/healthcheck-path: <healthcheck-path>
alb.ingress.kubernetes.io/success-codes: 200
spec:
defaultBackend:
service:
name: web-service
port:
number: 8000
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: web-service
port:
number: 8000If you want to enable TLS, replace the line
alb.ingress.kubernetes.io/listen-ports: '[{"HTTP": 80}]'with
alb.ingress.kubernetes.io/certificate-arn: <certificate-arn>
alb.ingress.kubernetes.io/ssl-policy: ELBSecurityPolicy-TLS-1-2-2017-01
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS": 443}]'After several minutes, the Ingress Load Balancer will be created. You check the status and external DNS address of it.
kubectl get ingress -o wideYou should able to browse the initial page now.
Background Tasks
Celery is deployed to run the background tasks such as the indexing of BibXML.
To run Celeery, create celery-deployment.yaml with suitable environments.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: celery
name: celery
spec:
replicas: 1
selector:
matchLabels:
app: celery
strategy:
type: Recreate
template:
metadata:
labels:
app: celery
spec:
containers:
- name: celery
image: <aws-account-id>.dkr.ecr.<aws-region>.amazonaws.com/<ecr-image-name>:latest
args:
- /bin/sh
- -c
- celery -A management worker -l info -c 1
env:
- name: DJANGO_SECRET
value: <django-secret>
- name: DB_HOST
value: <postgres-db-url>
- name: DB_PORT
value: "<db-port>"
- name: DB_USER
value: <db-user>
- name: DB_NAME
value: postgres
- name: DB_SECRET
value: <db-password>
- name: CELERY_BROKER_URL
value: redis://<redis-host>:<redis-port>
- name: CELERY_RESULT_BACKEND
value: redis://<redis-host>:<redis-port>
- name: REDIS_HOST
value: <redis-host>
- name: REDIS_PORT
value: "<redis-port>"
ports:
- containerPort: 5672To allow internal communication, you also need to create celery-service.yaml.
apiVersion: v1
kind: Service
metadata:
labels:
app: celery
name: celery-service
spec:
ports:
- name: "5672"
port: 5672
targetPort: 5672
selector:
app: celery
status:
loadBalancer: {}Apply changes by
kubectl apply -f celery-deployment.yaml
kubectl apply -f celery-service.yamlMonitor Background Tasks
If you want to monitor background tasks, you can use flower to monitor it.
Define flower in flower-deployment.yaml.
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: flower
name: flower
spec:
replicas: 1
selector:
matchLabels:
app: flower
strategy:
type: Recreate
template:
metadata:
labels:
app: flower
spec:
containers:
- name: flower
image: mher/flower
ports:
- containerPort: 5555
env:
- name: CELERY_BROKER_URL
value: <redis-url>
- name: CELERY_RESULT_BACKEND
value: <redis-url>If you want to access flower, you need to define flower-service.yaml.
apiVersion: v1
kind: Service
metadata:
labels:
app: flower
name: flower-service
spec:
ports:
- name: "5555"
port: 5555
targetPort: 5555
selector:
app: flower
status:
loadBalancer: {}Apply changes by
kubectl apply -f flower-deployment.yaml
kubectl apply -f flower-service.yamlNow, Bibxml service has been setup completely!
Links
Ribose is a cloud collaboration platform that makes working together easy and fun. Ribose is free to use: ribose.com.
The Internet Engineering Task Force (IETF) is a large open international community of network designers, operators, vendors, and researchers concerned with the evolution of the Internet architecture and the smooth operation of the Internet.
BibXML Service is Django-based Web service implementing IETF BibXML APIs.